
Nel lavoro quotidiano di chi produce e confeziona uva da tavola, l’errore spesso non si vede. Si parla infatti di falso negativo, quando cioè il grappolo con marciume o danni sfugge ai controlli e finisce in cassa. È qui che entra in gioco la visione artificiale, sempre più usata tra filari e linee di selezione. Ma c’è un problema strutturale, per cui i difetti reali sono pochi e variabili, stagione dopo stagione. Risultato: i sistemi “imparano” meno di quanto servirebbe. Di qui uno studio della Sapienza di Roma che, a partire da immagini reali di vigneto, ha costruito campioni di difetto sintetici ma realistici, così da allenare meglio i classificatori senza stravolgere la realtà del campo. L’idea nasce da un’esigenza concreta: ridurre i falsi negativi in un contesto in cui pochi punti percentuali fanno la differenza tra tutela della marca e successo del cliente.
- Leggi anche: Ready to eat: quali sono le varietà di uva ideali?
L’idea chiave: imitare i difetti
Il team ha lavorato in due vigneti a tendone nel sud del Lazio (circa 1,16 ha), con sesto 3×3 m su viti mature, protette da reti antipioggia e antigrandine: un contesto molto simile a quello reale di raccolta e selezione. La varietà scelta è stata Pizzutello Nero, ma l’approccio è pensato per estendersi anche ad altre uve. Le immagini sono state scattate con uno smartphone durante la stagione 2021, proprio per dimostrare che non servono attrezzature costose per costruire un dataset utile. Un agronomo ha poi classificato i campioni come “buoni” o “anomali” considerando marciumi, danni da insetti e altri difetti che incidono sulla qualità. Dalle foto sono stati estratti dei ritagli (patch), ottenendo 529 campioni “buoni” e 166 “anomali”.
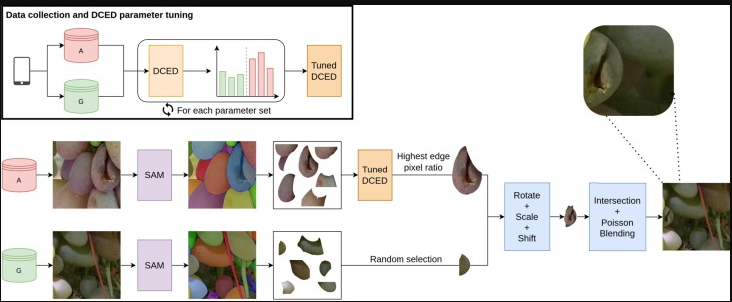
La sezione superiore del diagramma illustra le fasi preliminari della raccolta dati e della regolazione dei parametri DCED. La sezione inferiore descrive in dettaglio il processo di generazione del campione sintetico. Partendo da una coppia di campioni reali dal training set, il sistema utilizza SAM per estrarre le rispettive maschere. L’acino anomalo viene identificato prendendo la maschera con il rapporto pixel-bordo più elevato , come determinato dal DCED regolato. Al contrario, l’acino normale viene selezionato casualmente. Dopo aver ruotato, ridimensionato e spostato l’acino anomalo, calcoliamo l’intersezione delle due maschere. Infine, utilizziamo il blending di Poisson per unire gli acini e generare un nuovo campione sintetico.
Gli autori hanno tradotto un’osservazione semplice: l’acino sano è liscio, quello difettato ha una trama più irregolare. Per misurarla hanno applicato un doppio rilevamento dei bordi: prima hanno “allargato le maglie” per trovare molte linee, poi le hanno ristrette per tenere soprattutto quelle interne, tipiche delle anomalie. La differenza tra i due passaggi ha messo in evidenza la “ruvidità” del difetto e ha ridotto i contorni esterni, presenti anche negli acini sani. Hanno poi scelto i parametri provando diverse combinazioni e tenendo quelle con risultati più equilibrati; il semplice conteggio dei pixel di bordo è servito anche come termine di paragone.
Identificato l’acino sospetto, hanno usato un sistema che ha segmentato automaticamente le parti dell’immagine (acini sani, difettati, sfondo). Hanno tenuto solo le porzioni più grandi e pulite, scartando lo sfondo. L’acino anomalo è stato allineato e ridimensionato per combaciare con un acino sano dello stesso grappolo; infine lo hanno fuso nella nuova posizione con una tecnica che ha rispettato luci e colori, evitando l’effetto “figurina”.
In seconda battuta, è stata usata una rete neurale (ResNet-18) per distinguere grappoli “buoni” da “anomali”. Dopo un addestramento prolungato con semplici variazioni delle immagini (ribaltamenti orizzontali e piccoli cambi di colore), il metodo tradizionale basato su bordi si è fermato a circa 77 corretti su 100, mentre la rete ha riconosciuto quasi 95 su 100 con risultati molto stabili.
Su questa base si è testato l’effetto dei difetti sintetici in due modi: aggiungendone una quota (+10/+25/+50/+100% rispetto ai difetti reali) oppure sostituendone una parte (10/25/50/100%). Per evitare campioni “finti” poco visibili, si è provata anche una versione più evidente, incollando tre acini per ogni patch invece di uno.

Esempi di patch di immagini di uva da tavola e relativa estrazione dei bordi con un rilevatore di bordi Canny. A sinistra, è presente una patch (a) contenente acini in buone condizioni e il corrispondente risultato di rilevamento dei bordi (b). I bordi corrispondono al contorno esterno degli acini, mentre la superficie interna è liscia. L’immagine (c) mostra una patch contenente acini anomali. Il corrispondente risultato di rilevamento dei bordi (d) mostra una mappa dei bordi più complessa, che indica una consistenza più ruvida dovuta a difetti.
Cosa significa in pratica
Come sottolineano gli autori, sbagliare “in difetto” costa di più che essere troppo severi. Se un grappolo con problemi passa i controlli, possono arrivare reclami lungo la filiera o, in campo, il problema può estendersi ad altre piante. Detto questo, il materiale usato oggi è ancora limitato (zona, annata, coperture, una cultivar prevalente), quindi i risultati vanno verificati su dati nuovi e in condizioni diverse: lucentezza e colore degli acini, sfondi, stagioni. Anche il “come” si creano i difetti sintetici può migliorare: dalla scelta delle aree da ritagliare al modo in cui vengono fuse nell’immagine, con criteri più coerenti con il contesto agronomico per aumentarne il realismo.
Il messaggio chiave, però, è chiaro: con pochi campioni sintetici ben costruiti si sposta davvero l’ago della bilancia. E l’idea è trasferibile oltre l’uva, abbracciando molte altre specie frutticole.
- Leggi anche: Botrite, l’umidità spaventa anche la Sicilia
Ilaria De Marinis
©uvadatavola.com